数据库与网络运维 工程师与技术员的监控与故障解决之道

在当今以数据为驱动力的数字化时代,数据库服务器和网络设备构成了企业IT基础设施的核心支柱。确保这些系统的高可用性、安全性和性能,是工程师与技术员的核心职责。他们的工作远不止于被动响应故障,而是一个涵盖持续监控、主动维护与高效解决的闭环流程。
一、 全面监控:防患于未然的眼睛
有效的运维始于全面的监控。工程师和技术员会部署和使用一系列专业工具,对数据库和网络设备进行7x24小时不间断的观测。
- 数据库层面监控:重点关注关键性能指标(KPIs),如查询响应时间、连接数、锁等待、缓冲池命中率、磁盘I/O、CPU与内存利用率以及事务日志增长情况。通过监控,可以及时发现慢查询、资源瓶颈或潜在的数据一致性问题。
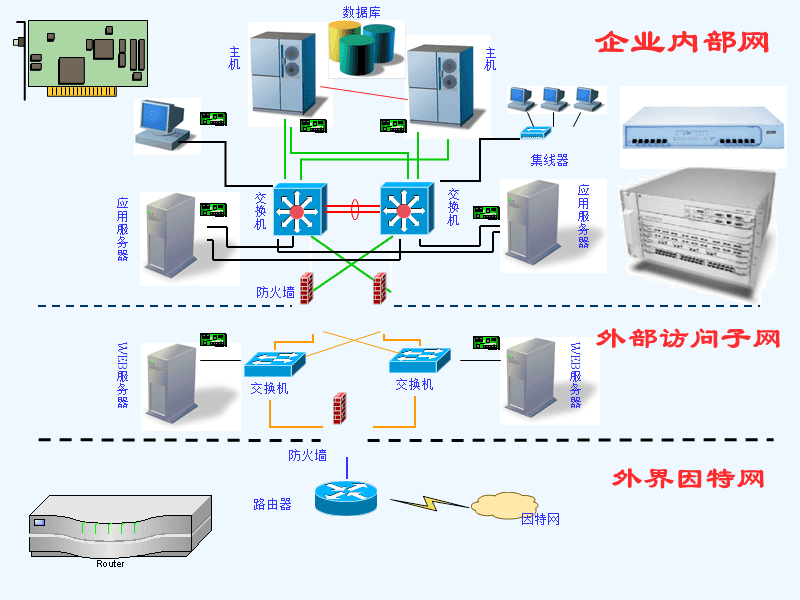
- 网络设备层面监控:核心在于保障连通性与性能。监控指标包括设备(如交换机、路由器、防火墙)的CPU/内存使用率、端口状态(up/down)、带宽利用率、丢包率、错误包计数以及网络延迟。这些数据有助于识别网络拥塞、硬件故障或配置错误。
监控系统会设置阈值告警,一旦指标异常,便会通过邮件、短信或集成平台(如Slack、钉钉)立即通知相关人员,实现从“人找故障”到“故障找人”的转变。
二、 精准诊断:定位问题的罗盘
当告警触发或用户报告服务异常时,工程师与技术员便进入诊断阶段。这是一个需要深厚知识体系和逻辑分析能力的过程。
- 问题分类与初步判断:首先需判断问题是出在数据库、网络,还是应用程序层,或是三者交织。例如,一个应用响应缓慢,可能是数据库慢查询导致,也可能是网络延迟引起。
- 利用工具深入排查:
- 数据库:使用
EXPLAIN分析查询执行计划,查看当前会话和锁信息,分析错误日志与慢查询日志。
- 网络:使用
ping测试基础连通性,traceroute追踪路径,netstat或ss查看连接状态,并深入分析网络设备日志与流量镜像数据。
- 根因分析:将监控数据与诊断工具的输出相结合,找出问题的根本原因。是硬件资源耗尽?是配置不当?是遭受攻击?还是版本升级引入的Bug?
三、 高效解决:恢复与优化之手
找到根因后,需迅速、稳妥地实施解决方案。
- 紧急恢复:对于严重影响业务的故障(如数据库宕机、核心网络中断),首要目标是快速恢复服务。措施可能包括:重启服务、故障切换(Failover)到备用节点、回滚有问题的配置或补丁、临时扩容资源等。所有操作应遵循变更管理流程,并在可行时于业务低峰期进行。
- 根本性修复:紧急恢复后,必须实施根本性修复以防止复发。这可能涉及:优化低效的SQL查询语句与索引;调整数据库参数配置;修复网络设备错误配置或升级固件;修复有缺陷的应用代码;对老化的硬件进行更换等。
- 优化与预防:解决问题后,工作并未结束。工程师需要分析事故,经验,改进监控告警阈值,优化架构设计(如引入读写分离、负载均衡),制定更完善的容灾备份策略,并编写运维文档与应急预案,将被动运维转化为主动优化。
四、 核心技能与挑战
胜任这份工作,需要工程师与技术员具备复合型技能:精通数据库(如Oracle, MySQL, PostgreSQL)原理与管理;深入理解TCP/IP协议栈及主流网络技术;熟练使用各类监控(如Prometheus, Zabbix)与诊断工具;掌握脚本语言(如Shell, Python)以实现自动化;并拥有强大的逻辑思维、抗压能力和沟通协作精神。
他们面临的挑战也日益严峻:云与混合环境下的复杂性、海量数据增长带来的性能压力、不断演进的安全威胁以及保障业务连续性的极高要求。
数据库与网络运维工程师及技术员,是企业数字脉络的“守护者”。他们通过专业的监控、敏锐的诊断和高效的解决,确保数据洪流在稳固的管道中顺畅奔涌,支撑起企业日常运营与创新发展的基石。他们的工作,是一场永不停歇的、在稳定与性能边界上的智慧守护。
如若转载,请注明出处:http://www.yiyixiacf.com/product/56.html
更新时间:2026-04-23 17:27:22